openstack中的协程¶
协程大概是在1963年(from wikipedia)左右提出的概念,较为突出的是Lua语言较早在自己的运行机制中加入了协程。大概2011年我在淘宝接触阿里的中间件团队,他们也较早的在生产环境中考虑使用协程来提高服务的并发能力,java领域的主要实现是Scala和Kilim。在python领域对协程的实现主要是greenlet库,以及基于greenlet实现的eventlet和gevent,本文主要介绍下openstack对协程的运用,以提高整个系统的并发能力。
C10K问题¶
网络服务在处理数以万计的客户端连接时,往往出现效率低下甚至完全瘫痪,这被称为C10K 问题,虽然现在硬件水平已经上来了,处理万级连接数已经不是问题,但是目前仍然用C10K来代表这一类问题。设计不够良好的程序,其性能和连接数及机器性能的关系往往也是非线性的。
系统性能低下主要由下面四大类问题引起:
- Data copy 数据拷贝
- Context switches CPU针对线程做的上下文切换
- Memory allocation 内存分配
- Lock contention 并发环境中的锁竞争
解决Data copy问题,hacker们发明了DMA、zero-copy等技术,数据在冷热存储介质中位置移动CPU将较少的参与,数据不会在用户态和内核缓冲区之间重复拷贝,而更多的是在存储介质中直接的位置移动。 随着硬件技术的发展,内存已经很少成为瓶颈,Memory allocation的影响逐渐减低了。 而对于Context switches和Lock contention,hacker们做的努力是不小的,AIO和协程的实现,大大提升了系统的并发性能。
推荐阅读材料:
什么是协程¶
协程(coroutine)通常是纯软件实现的多任务,与CPU和操作系统通常没有关系。现代编程语言基本上都有支持,比如 Lua、ruby 和最新的 Google Go,。协程是用户空间线程,操作系统其存在一无所知,所以需要用户自己去做调度,用来执行协作式多任务非常合适。其实用协程来做的东西,用线程或进程通常也是一样可以做的,但往往多了许多加锁和通信的操作。
协程的好处:
- 跨平台
- 跨体系架构
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销
协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。
假设有一个操作系统,是单核的,系统上没有其他的程序需要运行,有两个线程 A 和 B ,A 和 B 在单独运行时都需要 10 秒来完成自己的任务,而且任务都是运算操作,A B 之间也没有竞争和共享数据的问题。现在 A B 两个线程并行,操作系统会不停的在 A B 两个线程之间切换,达到一种伪并行的效果,假设切换的频率是每秒一次,切换的成本是 0.1 秒(主要是栈切换),总共需要 20 + 19 * 0.1 = 21.9 秒。如果使用协程的方式,可以先运行协程 A ,A 结束的时候让位给协程 B ,只发生一次切换,总时间是 20 + 1 * 0.1 = 20.1 秒。如果系统是双核的,而且线程是标准线程,那么 A B 两个线程就可以真并行,总时间只需要 10 秒,而协程的方案仍然需要 20.1 秒。
尽管协程不能使用CPU多核,但是我们可以用过多进程方式,每个进程里面运行协程的方式,来达到使用CPU多核的目的,这也是目前通用的作法。
openstack中的应用¶
openstack主要通过eventlet库来使用协程的,较为突出的应用场景是各个组件的API。API是HTTP Rest方式,是用过WSGI方式提供的,而WSGI Server都是通过eventlet实现的。大部分组件在这个部分的实现是一样的,所以我随意选取其中一个源码来分析下,看下面的核心代码:
def run_server(self):
"""Run a WSGI server."""
eventlet.wsgi.HttpProtocol.default_request_version = "HTTP/1.0"
try:
eventlet.hubs.use_hub()
self.logger.info(_('eventlet hub is %s') % eventlet.hubs.get_default_hub().__name__)
except Exception:
msg = _("eventlet '%s' hub is not available on this platform")
raise exception.WorkerCreationFailure(
reason=msg % cfg.CONF.eventlet_hub)
self.pool = self.create_pool()
try:
eventlet.wsgi.server(self.sock,
self.application,
log=logging.WritableLogger(self.logger),
custom_pool=self.pool,
debug=False)
except socket.error as err:
if err[0] != errno.EINVAL:
raise
self.pool.waitall()
eventlet已经做好了封装,简化了调用,另外值得注意的是,wsgi-server的实现需要用到python标准库,而这些标准库的内部实现还是用标准的线程,需要给标准库打patch,将标准线程替换为协程,eventlet有个monkey-patch的经典实现,只需要调用eventlet.patcher.monkey_patch()即可,这个调用,你在所有的openstack组件上都可以看到,monkey-patch的原理本文不做讨论。
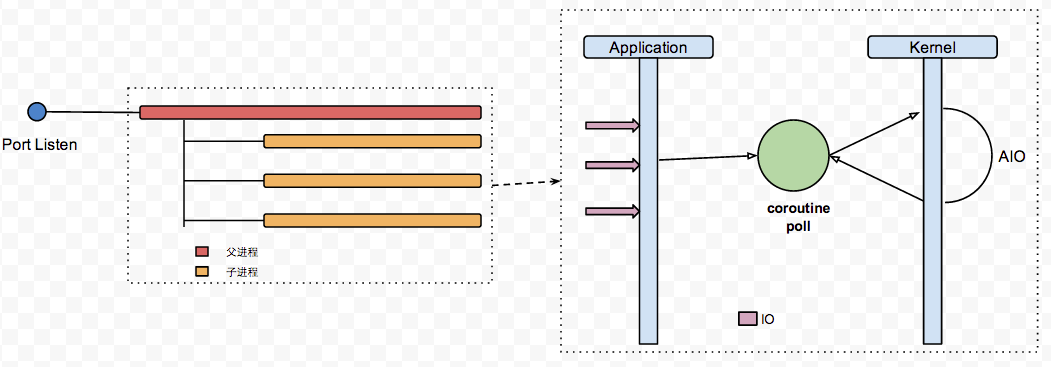
在利用多核方面,openstack的实现方式是使用父进程进行任务分配调度,多个子进程提供服务,通常这里子进程的数量我们是可以配置的,一般配置成和CPU核数一样,以达到最高效率,每个子进程内部实现协程池,并自己调度协程切换,减少CPU的消耗。
eventlet.hubs.use_hub()也是十分重要的,设置之后,default_hub的值会根据系统不同而调整,Linux会选择epoll,FreeBSD会选择kqueen,这两者都是在各自系统实现AIO,这使得线程处理IO的时候可以使用异步回调机制,大幅度提升CPU的运行效率。但是,我们已经抛弃了线程使用协程,协程并不能被系统感知而使用AIO,use_hub()正是实现了协程也能使用AIO。
最后整体看下这张图,有助于消化理解:
使用中的问题¶
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,当你使用线程,那么主线程又可以启动新的线程,如果你使用协程,那么主线程去启动一些协程。 但是协程并不是完美的,也会有很多问题,在openstack中,会有如下问题:
- there is only one operating system thread, a call that blocks that main thread will block the entire process.
- the long-running thread will block any pending threads.
- openstack访问mysql使用的是C库,eventlet不能对其使用monkey-patch,所以进行mysql CRUD的时候会阻塞main thread
参考: http://docs.openstack.org/developer/nova/devref/threading.html